Voice can provide a simple, compelling user experience, but the path to adding voice controls to any product, service or application is complex. As dominant tech players continue to develop voice-enabled interfaces and assistants, product designers, developers and manufacturers will be forced to rethink the user experience and user interface.
With the incredible expansion of smart speaker adoption and consumers’ tendency to purchase smart home devices as point solutions rather than as a system, many homes in the future will have a distributed intelligence platform with voice control acting as the primary user interface.
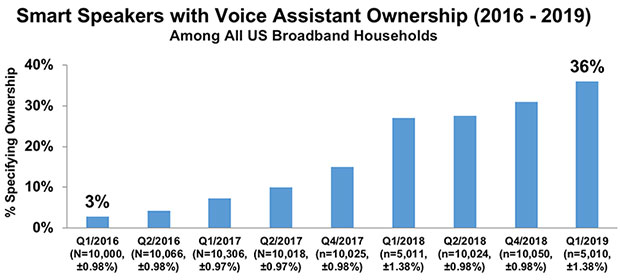
In early 2019, 36 percent of US broadband households owned at least one smart speaker with a voice assistant.
Voice assistant technology relies on two main components: the hardware, a way to communicate and capture commands; and the software, a way to think and to process a response. While hardware and software decisions are important, considerations of other factors — such as local versus cloud processing, and power consumption — also can have a significant impact on the success of a voice-first application or device.
Hardware Design
Designing for voice requires manufacturers to evaluate their end product and make decisions regarding context of use, the environment in which the device will be used, and the consumer interaction model. These decisions impact hardware choices.
For instance, an assessment of the device’s environment in terms of spatial awareness, potential noise levels in the room, and the user’s proximity to the device when speaking may lead to the implementation of more or fewer microphones.
To enable voice recognition, a device must be Internet-connected and include a microphone and a speaker. Other components include analog-to-digital converters (ADC), digital signal processors (DSP), and digital-to-analog converters (DAC).
During the input stage, when a user speaks to a device, the microphone will capture the phrase and send it to an ADC, which converts the voice input into digital audio data. Microphones may be analog or digital. Analog microphones must be paired with an analog-digital converter while digital microphones have one built in.
Design in a microphone array depends on the environment of the device. For those that require the user to speak close to the device, one to two microphones are ideal. Far-field communication may require a four-to-seven microphone array.
After the input stage comes the processing stage. The digital signal processor feed the data to the network module and natural language processing engine. During this stage, algorithms are instigated over the captured voice data.
Beamforming, dynamic range compression and adaptive spectral noise reduction are examples of algorithms that help to improve the quality of the voice data captured. Upon completion of the processing stage, the data is sent to the digital-analog-convertor and amplifier for output to the user.
Software Requirements
The building blocks for creating the software infrastructure for voice-first technology include natural language processing, which includes automatic speech recognition (ASR) and natural language understanding (NLU); wake word algorithms to initiate the voice response process; and a cloud platform to process the data.
The wake word serves as the gateway between the user and the voice assistant. The wake word engine is an algorithm that activates the voice interface of a device by monitoring audio signals to detect a specific word of interest.
Once a predetermined trigger word or phrase is detected, the voice query is sent to the cloud for processing. Generally, this technology runs locally, on device, to improve latency in voice query response and safeguard privacy.
Natural Language Processing (NLP) is a form of artificial intelligence that enables human-machine interaction using natural dialogue through text, voice or both. Chatbots generally refer to text-based dialog systems, whereas voicebots refer to voice-first assistants like Alexa or Google Assistant.
In a simplified NLP architecture, automated speech recognition (ASR) identifies words that are spoken and converts them to text (speech-to-text).
Local vs. Cloud Processing
Companies seeking to design for voice-first technology must decide how their voice assistant will process voice queries — whether in the cloud or locally on a device. Considerations in response speed, connection to the Internet, and security all factor into the decision.
DSP Group, a voice chipmaker, has found that it is feasible to implement a certain number of simple commands on fairly low-end processors or DSP chips. It has found that the sweet spot for the number of simple commands locally falls at five to 10 commands.
These commands include tasks such as turning a device on and off, and lowering and increasing the volume. Once the number of commands moves beyond 10 to15, the need for more memory and processing power, and the risk of higher fault detection rates increase substantially.
This indicates the shift to cloud processing. More complex commands are sent to the cloud due to the need for more power and flexibility while a limited subset of commands can be interpreted locally.
Privacy concerns with always-on listening devices are a key barrier to adoption of voice-first devices. Furthermore, consumers harbor little trust for device manufacturers in accessing and managing their personal data.
Power Inputs/Consumption
Manufacturers must take into consideration the power consumption of processors running algorithms for natural language processing. Devices that lack a dedicated power source benefit from low-energy solutions. A power-aware design for always-on listening features associated with voice-enabled devices is key for power optimization.
Current smart speakers have dedicated AC power due to the energy consumption of always-listening technology. Companies may opt for battery power over AC power for a number of reasons, such as physical placement of the device and the luxury of freedom of device placement in a room.
Aesthetics also may be a factor in removing power cords from the device, particularly for devices that historically were battery-powered before implementing voice recognition technology.
Voice-enabled TV remotes are battery-powered devices that require consumers to change the batteries every three to four months. Some companies, such as Comcast, have opted for the push-to-talk feature instead of hands-free for voice remotes to lengthen battery life.
Power consumption can be approached in a variety of ways. Reduction in the use of power may be implemented through the use of unique wake word technology, the number of voice commands integrated, and algorithms initiated on a device.
As the consumer electronics industry continues to explore voice interfaces in smaller devices and form factors, demand for ultra-efficient and low-power solutions will increase.
As smart home device ownership increases, with owners often having multiple devices, voice as a centralized user interface for the home will grow in importance. Interoperability serves as a driving factor. Voice will become a key interface to alleviate smart home complexity and fragmentation.